
META LLAMA 3 爆炸登场!在线试用、本地部署,性能直逼 GPT-4!

META LLAMA 3 爆炸登场!在线试用、本地部署,性能直逼 GPT-4!
罗布斯# Meta 宣布推出革命性开源大语言模型 Llama 3!
Meta 正式发布了下一代开源大语言模型 Llama 3,这标志着 AI 发展的新里程碑!该模型分为 80 亿和 700 亿参数两个版本,
被誉为 “Llama 2 的重大飞跃”,为大规模语言模型树立新标杆。
# Llama 3 的未来之路
值得一提的是,Llama 3 已与 Meta AI 助手深度集成,未来还将陆续在 AWS、Databricks、Google Cloud 等多个云平台上线,
并获得 AMD、Intel、NVIDIA 等硬件厂商的支持,进一步扩大应用场景。
这将为 Llama 3 带来无限的可能!
# Meta 的开源 AI 决心
该模型的发布彰显了 Meta 在开源 AI 领域的决心和影响力。我们有理由期待,Llama 3 将为自然语言处理、机器学习等 AI 前沿技术的发展注入新动力。
期待 Llama 3 的未来!
# 三种使用方式
- 在线使用(
推荐) - 本地直连使用
- 套壳使用
- API 方式调用(
推荐)
# 在线使用
入口:链接直达
不仅可以智能对话,也可以在线生成图片
# 本地直连使用
-
从 github 下载 Llama 3 项目文件:
点击下载 -
申请模型下载链接(申请秒过),申请后会在邮件里提供一个下载链接:
点击申请 -
环境依赖安装
1
2在Llama3最高级目录执行以下命令(建议在安装了python的conda环境下执行)
pip install -e . -
下载 Llama3 模型
1
bash download.sh
-
运行命令后在终端下输入邮件里获取到下载链接,并选择你需要的模型
-
运行示例脚本,执行以下命令
1
2
3
4torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir Meta-Llama-3-8B-Instruct/ \
--tokenizer_path Meta-Llama-3-8B-Instruct/tokenizer.model \
--max_seq_len 512 --max_batch_size 6 -
创建自己的对话脚本,在根目录下创建以下 chat.py 脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49from typing import List, Optional
import fire
from llama import Dialog, Llama
def main(
ckpt_dir: str,
tokenizer_path: str,
top_p: float = 0.9,
max_seq_len: int = 512,
max_batch_size: int = 4,
max_gen_len: Optional[int] = None,
):
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
# Modify the dialogs list to only include user inputs
dialogs: List[Dialog] = [
[{"role": "user", "content": ""}], # Initialize with an empty user input
]
# Start the conversation loop
while True:
# Get user input
user_input = input("You: ")
# Exit loop if user inputs 'exit'
if user_input.lower() == 'exit':
break
# Append user input to the dialogs list
dialogs[0][0]["content"] = user_input
# Use the generator to get model response
result = generator.chat_completion(
dialogs,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)[0]
# Print model response
print(f"Model: {result['generation']['content']}")
if __name__ == "__main__":
fire.Fire(main) -
运行以下命令就可以开始对话
1
torchrun --nproc_per_node 1 chat.py --ckpt_dir Meta-Llama-3-8B-Instruct/ --tokenizer_path Meta-Llama-3-8B-Instruct/tokenizer.model --max_seq_len 512 --max_batch_size 6
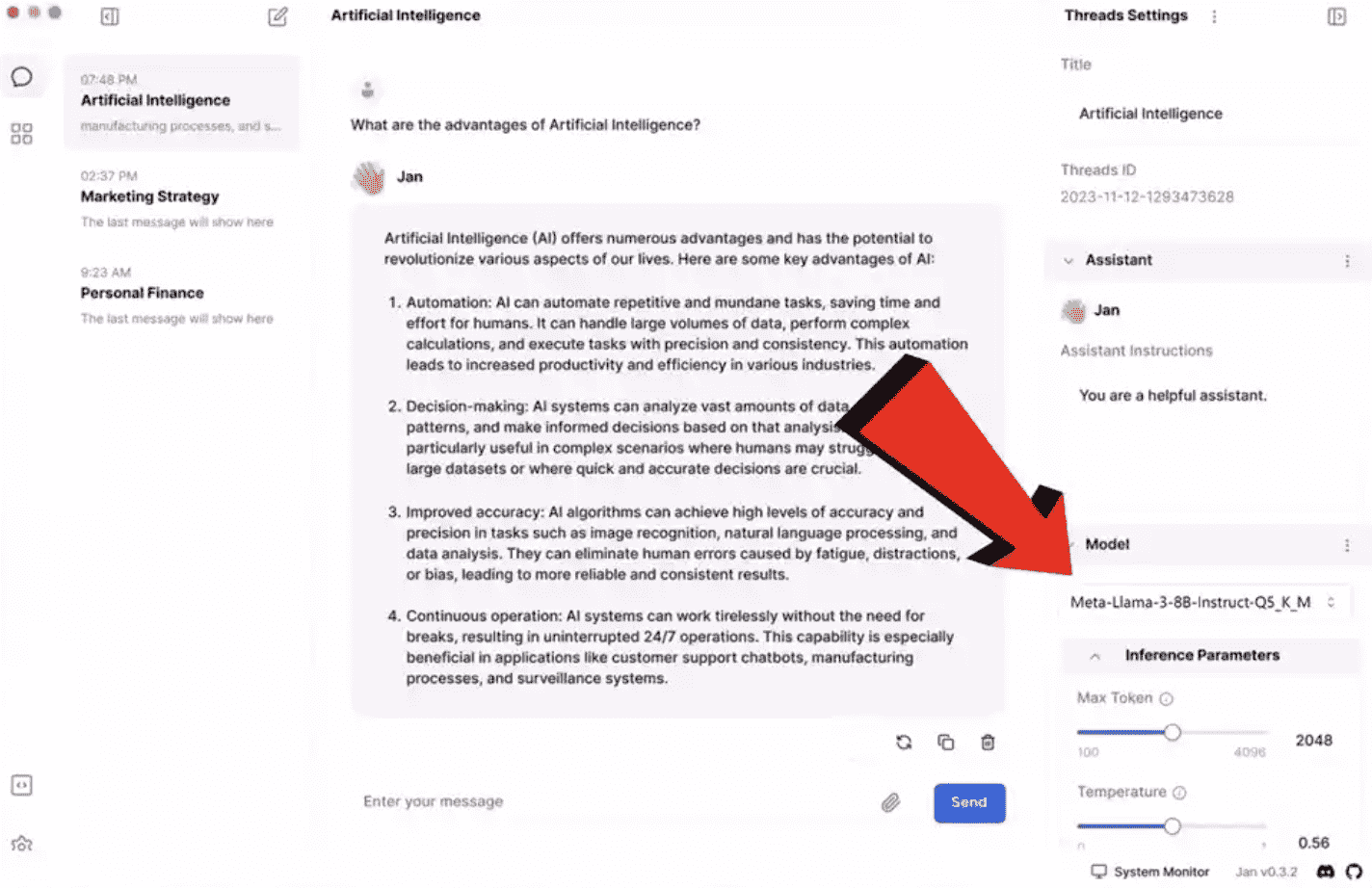
# 套壳使用
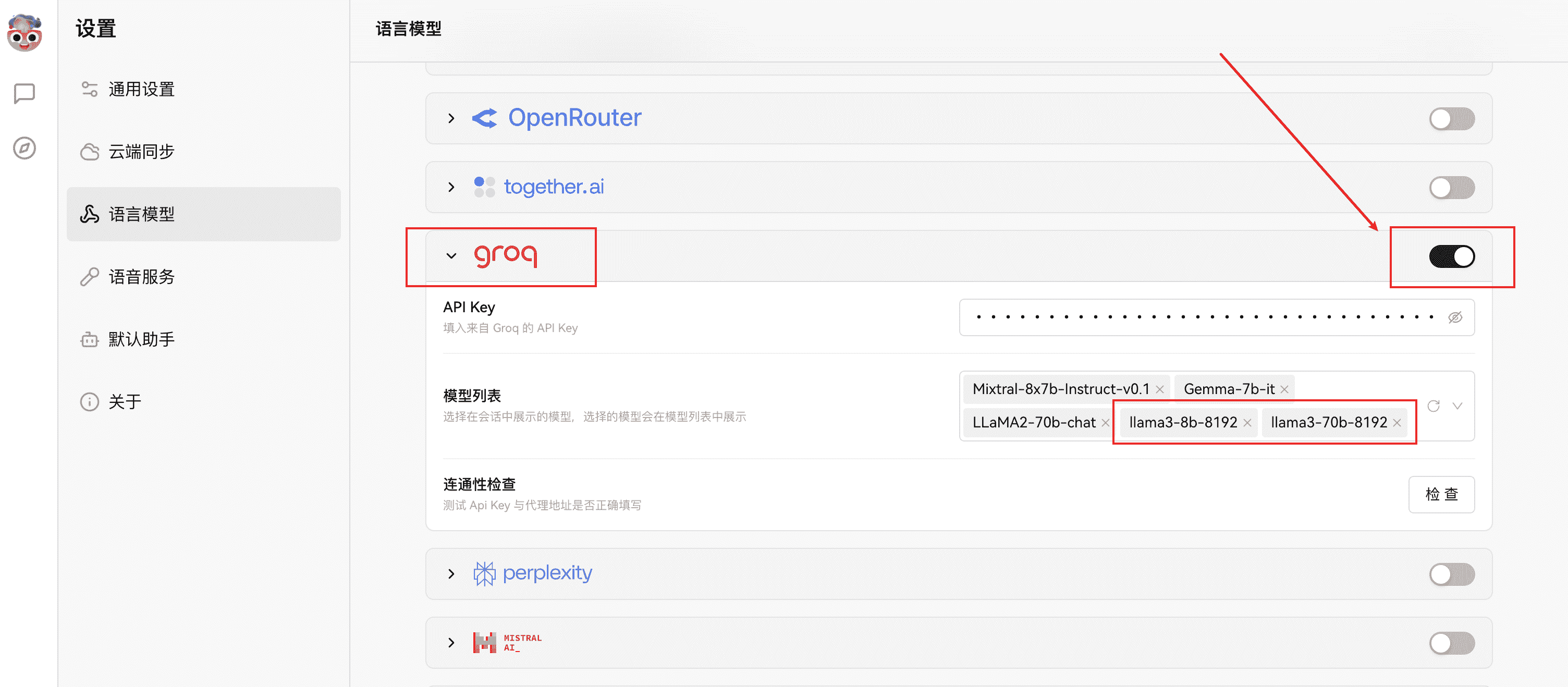
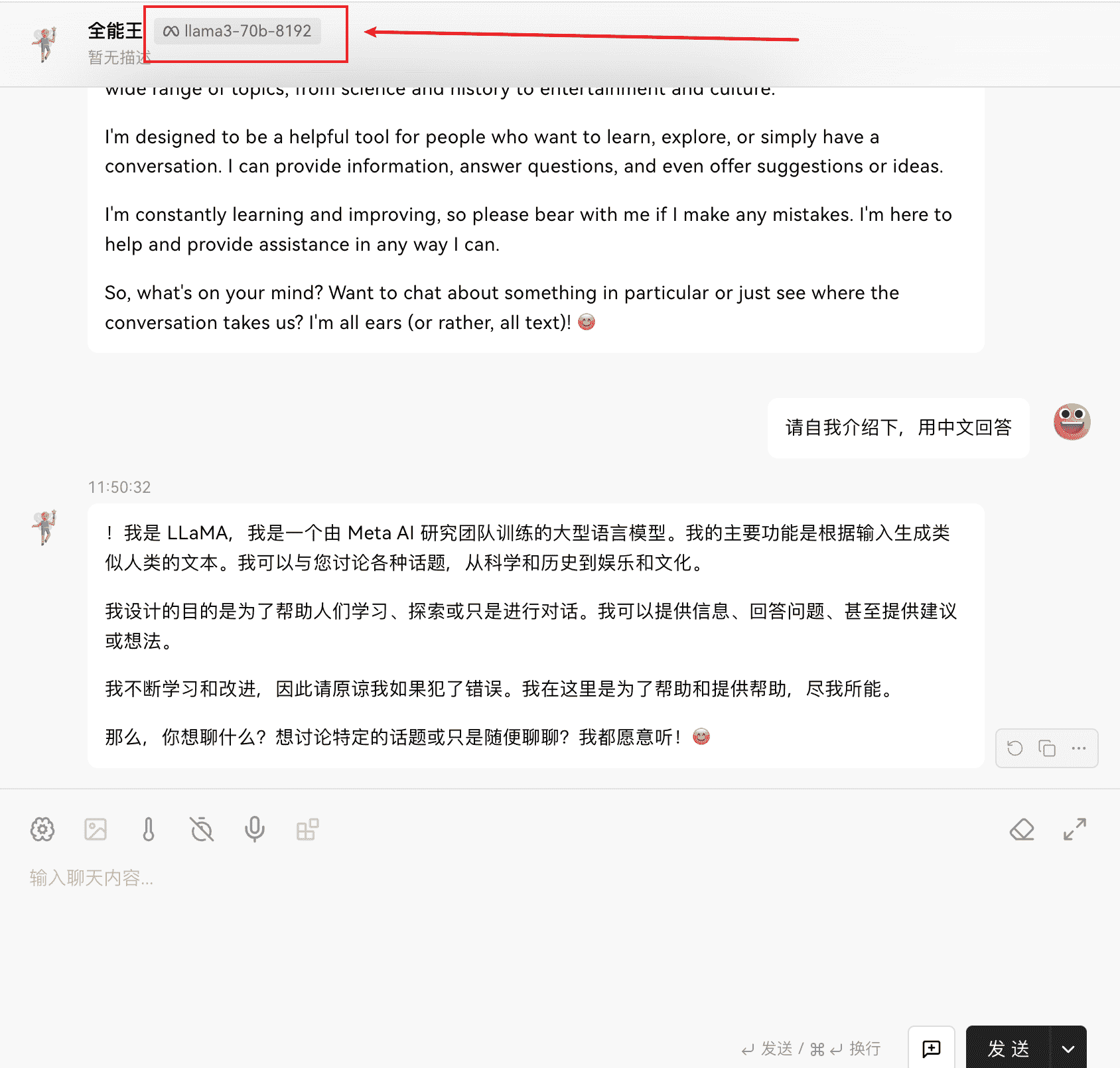
# API 方式调用


喜欢这篇文章的人也看了






评论
匿名评论隐私政策
TwikooGitalk
✅ 你无需删除空行,直接评论以获取最佳展示效果








